



1 237 616 доменов сайтов, созданных когда-то на платформе narod.ru
уникальные тексты
веселые изображения
личные дневники, фанклубы, сайты учреждений и т.д.
сайты с большим числом рекламы, возможно остаточное наличие сайтов с неприемлемым контентом
эти данные есть только у нас
уникальные тексты
веселые изображения
личные дневники, фанклубы, сайты учреждений и т.д.
сайты с большим числом рекламы, возможно остаточное наличие сайтов с неприемлемым контентом
эти данные есть только у нас

-Масштабность - Уникальность - Разнонаправленность
О проекте

1 237 616 доменов сайтов, созданных когда-то на платформе narod.ru
уникальные тексты
веселые изображения
личные дневники, фанклубы, сайты учреждений и т.д.
сайты с большим числом рекламы, возможно остаточное наличие сайтов с неприемлемым контентом
эти данные есть только у нас
уникальные тексты
веселые изображения
личные дневники, фанклубы, сайты учреждений и т.д.
сайты с большим числом рекламы, возможно остаточное наличие сайтов с неприемлемым контентом
эти данные есть только у нас
-Масштабность
- Уникальность
- Разнонаправленность
- Уникальность
- Разнонаправленность
О проекте
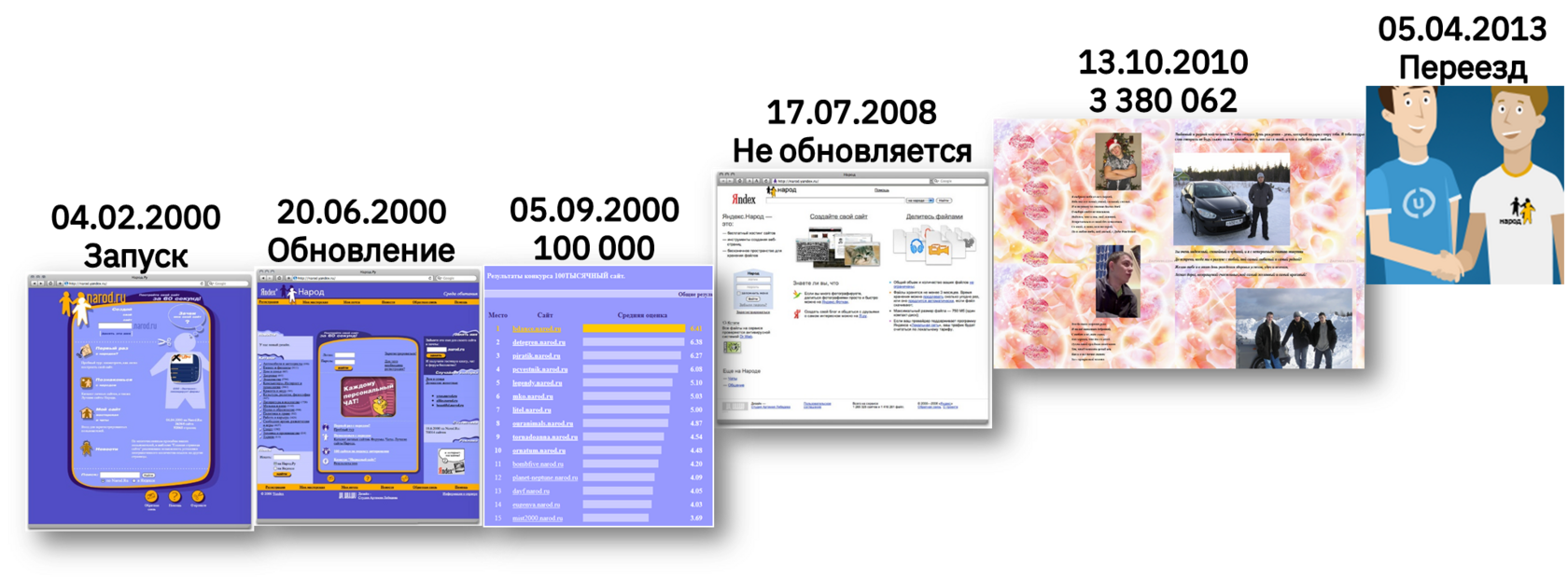

«Лихие 2000-е» Рунета.
Главные вехи развития народа
Главные вехи развития народа

04.02.2000
Запуск хостинга
Запуск хостинга
20.06.2000
Обновление
Обновление
05.09.2000
100 000 сайтов
100 000 сайтов
07.17.2008
Не обновляется
Не обновляется
13.10.2010
3 млн страниц
3 млн страниц
05.04.2013
Переезд на ucoz
Переезд на ucoz

История Naroda
В рамках проекта «Narod и цифровое наследие» мы работали с данными сайтов, созданных на базе бесплатного хостинга интернет-сервиса Яндекс.Народ.
Само название хостинга и условия, на которых он предоставлялся пользователям (неограниченное пространство для хранения данных, свобода в выборе стиля, минимальное количество контекстной рекламы, простота в использовании), сделали его в прямом смысле народным. Запущенный в январе 2000 г. сервис, уже через девять месяцев имел 100 000 сайтов.
На пике своего развития в 2010 году Narod насчитывал 3 380 062 сайта и 21 787 893 файла. Через 13 лет после создания хостинга Яндекс передал его веб-сервису uCoz, объяснив это снижением его популярности.
За период своего существования Narod стал той площадкой, где люди пробовали создавать первые сайты, рассказывая о себе, своих интересах, компаниях, им даже пользовались органы власти и крупные культурно-образовательные учреждения.
В рамках проекта мы рассматриваем Narod как памятью рунета 2000-х гг., а активные эксперименты с возможностями новой среды при выборе дизайна сайтов позволяют его определить как «лихие 2000-е» народного преимущественно (но не только) русскоязычного сегмента интернета.
Само название хостинга и условия, на которых он предоставлялся пользователям (неограниченное пространство для хранения данных, свобода в выборе стиля, минимальное количество контекстной рекламы, простота в использовании), сделали его в прямом смысле народным. Запущенный в январе 2000 г. сервис, уже через девять месяцев имел 100 000 сайтов.
На пике своего развития в 2010 году Narod насчитывал 3 380 062 сайта и 21 787 893 файла. Через 13 лет после создания хостинга Яндекс передал его веб-сервису uCoz, объяснив это снижением его популярности.
За период своего существования Narod стал той площадкой, где люди пробовали создавать первые сайты, рассказывая о себе, своих интересах, компаниях, им даже пользовались органы власти и крупные культурно-образовательные учреждения.
В рамках проекта мы рассматриваем Narod как памятью рунета 2000-х гг., а активные эксперименты с возможностями новой среды при выборе дизайна сайтов позволяют его определить как «лихие 2000-е» народного преимущественно (но не только) русскоязычного сегмента интернета.
История Naroda
В рамках проекта «Narod и цифровое наследие» мы работали с данными сайтов, созданных на базе бесплатного хостинга интернет-сервиса Яндекс.Народ.
Само название хостинга и условия, на которых он предоставлялся пользователям (неограниченное пространство для хранения данных, свобода в выборе стиля, минимальное количество контекстной рекламы, простота в использовании), сделали его в прямом смысле народным. Запущенный в январе 2000 г. сервис, уже через девять месяцев имел 100 000 сайтов.
На пике своего развития в 2010 году Narod насчитывал 3 380 062 сайта и 21 787 893 файла. Через 13 лет после создания хостинга Яндекс передал его веб-сервису uCoz, объяснив это снижением его популярности.
За период своего существования Narod стал той площадкой, где люди пробовали создавать первые сайты, рассказывая о себе, своих интересах, компаниях, им даже пользовались органы власти и крупные культурно-образовательные учреждения.
В рамках проекта мы рассматриваем Narod как памятью рунета 2000-х гг., а активные эксперименты с возможностями новой среды при выборе дизайна сайтов позволяют его определить как «лихие 2000-е» народного преимущественно (но не только) русскоязычного сегмента интернета.
Само название хостинга и условия, на которых он предоставлялся пользователям (неограниченное пространство для хранения данных, свобода в выборе стиля, минимальное количество контекстной рекламы, простота в использовании), сделали его в прямом смысле народным. Запущенный в январе 2000 г. сервис, уже через девять месяцев имел 100 000 сайтов.
На пике своего развития в 2010 году Narod насчитывал 3 380 062 сайта и 21 787 893 файла. Через 13 лет после создания хостинга Яндекс передал его веб-сервису uCoz, объяснив это снижением его популярности.
За период своего существования Narod стал той площадкой, где люди пробовали создавать первые сайты, рассказывая о себе, своих интересах, компаниях, им даже пользовались органы власти и крупные культурно-образовательные учреждения.
В рамках проекта мы рассматриваем Narod как памятью рунета 2000-х гг., а активные эксперименты с возможностями новой среды при выборе дизайна сайтов позволяют его определить как «лихие 2000-е» народного преимущественно (но не только) русскоязычного сегмента интернета.
Цифровое наследие: анализ и сохранение
Narod – отдельный этап в истории развития цифрового пространства,
«память» Рунета 2000-х гг.
Глобальная цель - изучение цифрового наследия, не имеющего физических аналогов.
Направления и возможности:
«память» Рунета 2000-х гг.
Глобальная цель - изучение цифрового наследия, не имеющего физических аналогов.
Направления и возможности:
- Культурологический анализ: трансформация цифровой культуры, визуальных и текстовых трендов
- Исторический анализ: тенденции развития Рунета, влияние внешнего контекста на содержание сайтов Narod.ru
- Антропосоциологический анализ: веб как средство самовыражения и общения, динамика социального интернет-пространства

«Карта мира масштабом 1:1»?
Цифровое наследие: анализ и сохранение
Narod – отдельный этап в истории развития цифрового пространства,
«память» Рунета 2000-х гг.
Глобальная цель - изучение цифрового наследия, не имеющего физических аналогов.
Направления и возможности:
«память» Рунета 2000-х гг.
Глобальная цель - изучение цифрового наследия, не имеющего физических аналогов.
Направления и возможности:
- Культурологический анализ: трансформация цифровой культуры, визуальных и текстовых трендов
- Исторический анализ: тенденции развития Рунета, влияние внешнего контекста на содержание сайтов Narod.ru
- Антропосоциологический анализ: веб как средство самовыражения и общения, динамика социального интернет-пространства
«Карта мира масштабом 1:1»?
(Со)Хранить и изучить Narod
Глобальная проблема, над которой мы работали в рамках проекта - сохранение цифрового наследия, не имеющего физических аналогов, анализируя Narod и web 1.0 в целом как отдельный этап в истории развития цифрового пространства.
Наша цель – сохранение контента для дальнейшего содержательного анализа культурного наследия, изучения истории развития интернета как отдельного пласта культуры, среды репрезентации окружающего физического мира, т.к. существует реальная угроза утраты этого культурного слоя.Кроме того, проект позволяет говорить об эволюции не только инструментов создания цифрового пространства, но и восприятия человека в нем.
Работая в рамках научного направления веб-археологии, мы ищем актуальную и содержательную информацию, которая часто скрыта в слоях кода, огромных объемах данных, структурах сайтов, связей и объектах веб-сайтов.
Наша цель – сохранение контента для дальнейшего содержательного анализа культурного наследия, изучения истории развития интернета как отдельного пласта культуры, среды репрезентации окружающего физического мира, т.к. существует реальная угроза утраты этого культурного слоя.Кроме того, проект позволяет говорить об эволюции не только инструментов создания цифрового пространства, но и восприятия человека в нем.
Работая в рамках научного направления веб-археологии, мы ищем актуальную и содержательную информацию, которая часто скрыта в слоях кода, огромных объемах данных, структурах сайтов, связей и объектах веб-сайтов.

(Со)Хранить и изучить Narod
Глобальная проблема, над которой мы работали в рамках проекта - сохранение цифрового наследия, не имеющего физических аналогов, анализируя Narod и web 1.0 в целом как отдельный этап в истории развития цифрового пространства.
Наша цель – сохранение контента для дальнейшего содержательного анализа культурного наследия, изучения истории развития интернета как отдельного пласта культуры, среды репрезентации окружающего физического мира, т.к. существует реальная угроза утраты этого культурного слоя.Кроме того, проект позволяет говорить об эволюции не только инструментов создания цифрового пространства, но и восприятия человека в нем.
Работая в рамках научного направления веб-археологии, мы ищем актуальную и содержательную информацию, которая часто скрыта в слоях кода, огромных объемах данных, структурах сайтов, связей и объектах веб-сайтов.
Наша цель – сохранение контента для дальнейшего содержательного анализа культурного наследия, изучения истории развития интернета как отдельного пласта культуры, среды репрезентации окружающего физического мира, т.к. существует реальная угроза утраты этого культурного слоя.Кроме того, проект позволяет говорить об эволюции не только инструментов создания цифрового пространства, но и восприятия человека в нем.
Работая в рамках научного направления веб-археологии, мы ищем актуальную и содержательную информацию, которая часто скрыта в слоях кода, огромных объемах данных, структурах сайтов, связей и объектах веб-сайтов.
Сбор данных
сбор html-контента и текста главных страниц
сбор внутренних ссылок
сбор внутренних ссылок
Направления работы

сбор html-контента и текста всех страниц
создание серверной распределенной базы данных для хранения данных
Сбор данных
сбор html-контента и текста главных страниц
сбор внутренних ссылок
сбор внутренних ссылок
Направления работы
сбор html-контента и текста всех страниц
создание серверной
распределенной базы данных
для хранения данных
распределенной базы данных
для хранения данных


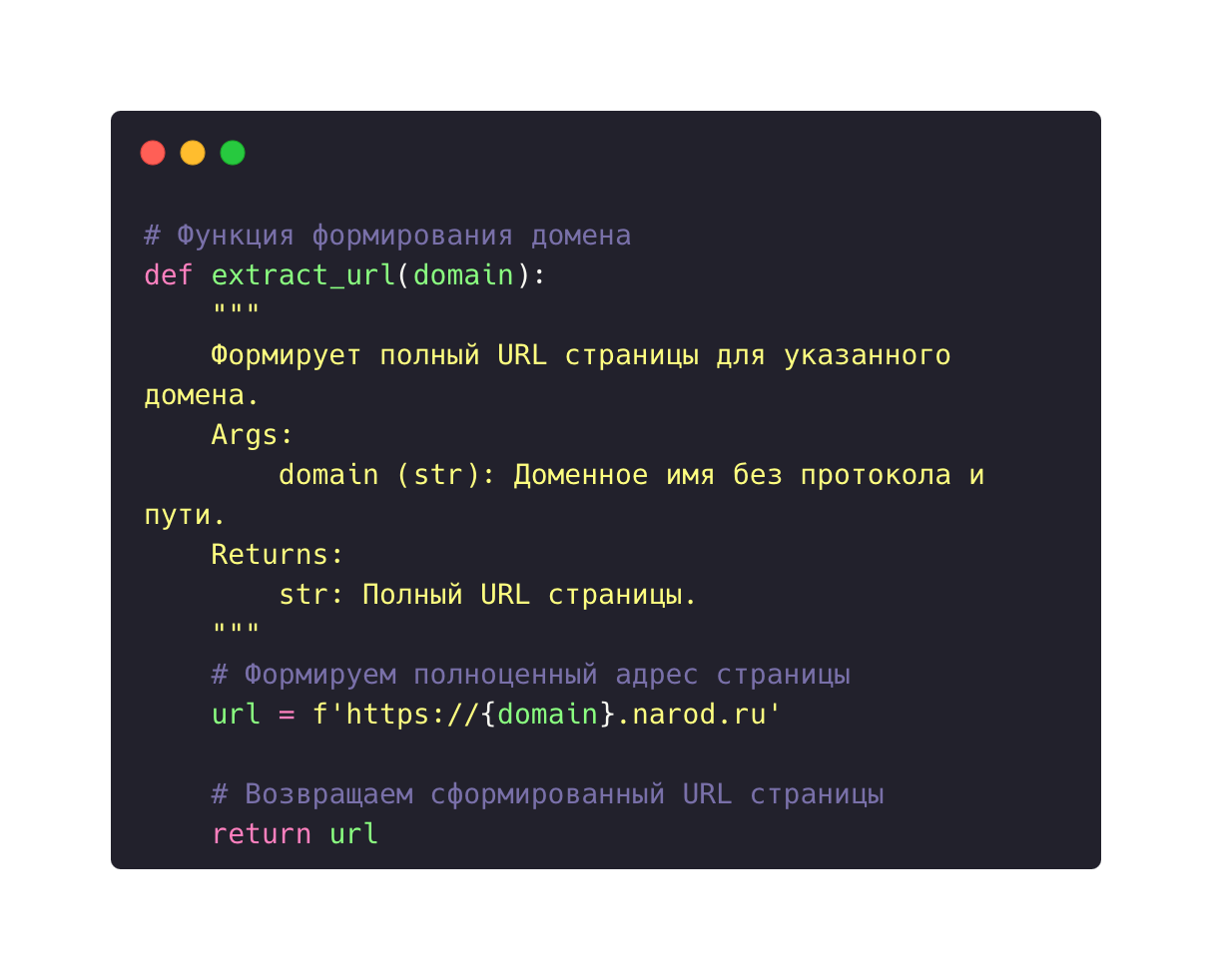
Формирование полныхадресов главных страниц
Формирование адреса главной страницы сайта для доступа к данным.
Скрэпинг HTML-документов главных страниц
Очистка HTML- документов от рекламы Ucoz
Удаление элементов HTML DOM дерева, содержащие рекламные блоки хостинга Ucoz.
Первым шагом, необходимым для доступа к сайтам, является формирование полных адресов страниц для дальнейшего обращения по ним с помощью отправки HTTP запросов
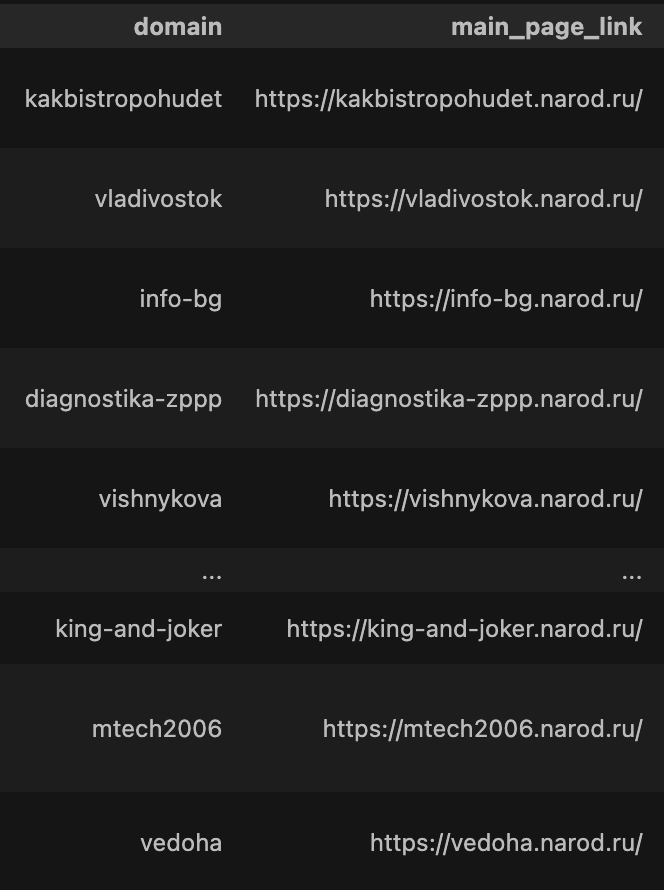
Результаты преобразования имен доменов в полные адреса
Сбор html-документов главных страниц для доступа к ее элементам.

Диаграмма последовательности работы алгоритма по сбору html документов главных страниц
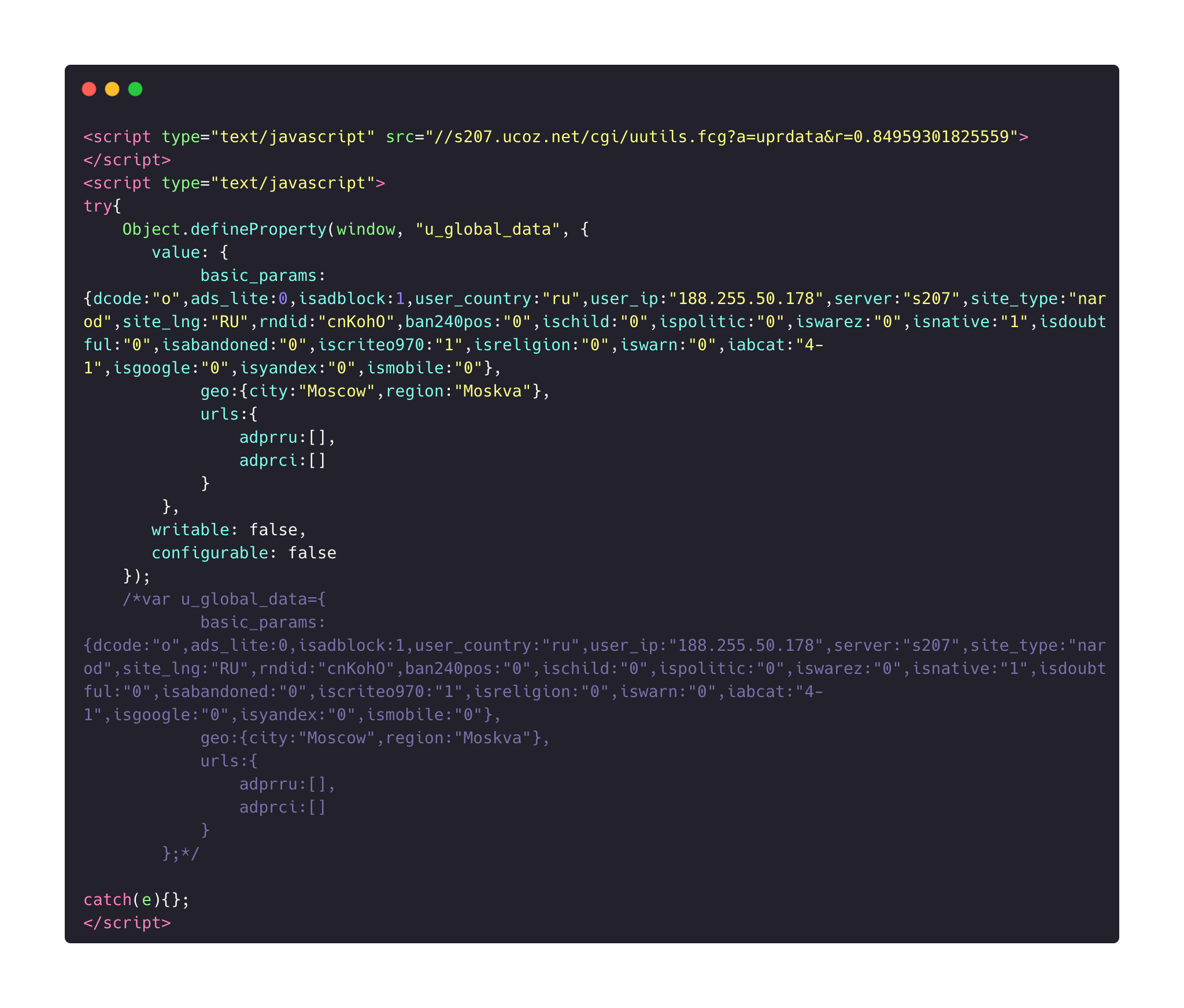
После миграции сайтов "народа "на хостинг Ucoz, абсолютно во все сайты были интегрированы рекламные блоки данной компании, что с точки зрения анализа html структуры сайтов является "шумом" данных, который требовалось очищать для дальнейшего корректного анализа текстов.
Пример скрипта рекламы Ucoz в коде страницы:
В результате анализа устройства подобный рекламных блоков
нам удалось разработать инструмент их очистки,
что позволило не только удалить "шум", но и уменьшить
размер самих данных.
нам удалось разработать инструмент их очистки,
что позволило не только удалить "шум", но и уменьшить
размер самих данных.
После очистки html-структур от рекламы Ucoz, с каждой главной страницы с помощью пакета BeautifulSoup был извлечен текст, для проведения дальнейшего анализа на его основе.
Успешно собранные HTML-структуры главных страниц не дают полное представление о природе и устройстве сайта: на главных страницах может быть мало контента или главная страница может представлять из себя приветственный блок к кнопкой "Войти на сайт". Подобные случаи на выходе дают очень мало информации, что препятствует их дальнейшему анализу.
Помимо этого, нужно помнить об уникальности и авторском подходе для каждого из сайтов. Дизайн сайтов народа не содержит определенного паттерна проектирования, на который можно было ориентироваться - каждая страница каждого сайта может содержать уникальную верстку, цвет и семейство шрифтов, а также различный медиа контент.
Чтобы полностью описать характеристики сайта с точки зрения данных, необходимо собрать информацию о со всех его страниц.
Помимо этого, нужно помнить об уникальности и авторском подходе для каждого из сайтов. Дизайн сайтов народа не содержит определенного паттерна проектирования, на который можно было ориентироваться - каждая страница каждого сайта может содержать уникальную верстку, цвет и семейство шрифтов, а также различный медиа контент.
Чтобы полностью описать характеристики сайта с точки зрения данных, необходимо собрать информацию о со всех его страниц.
Главная особенность процесса сбора контента с внутренних ссылок - частота запросов к одному и тому же сайту. Неправильная организация HTTP запросов к серверу, отсутствие задержек и маскировок на стороне клиента могут привести к блокировке со стороны хостинга, который в свою очередь детектирует и пытается предотвратить массовый сбор данных с его ресурса.
Также нужно учитывать, что в выборке с большой вероятности есть сайты, с большим количеством внутренних страниц и контентом на них, что делает неэффективным последовательное обращение и последующий сбор данных с каждого ресурса.
Учитывая данные особенности, мы разработали пайплайн сбора внутренних ссылок и последующего сбора их HTML-документов и текстов, используя следующие подходы:
Также нужно учитывать, что в выборке с большой вероятности есть сайты, с большим количеством внутренних страниц и контентом на них, что делает неэффективным последовательное обращение и последующий сбор данных с каждого ресурса.
Учитывая данные особенности, мы разработали пайплайн сбора внутренних ссылок и последующего сбора их HTML-документов и текстов, используя следующие подходы:
позволяет имитировать подключение с разных устройств, совершая запросы с одного устройства, что уменьшает вероятность блокировки со стороны хочтинга


при получении ошибки HTTP первого запроса к ресурсу, мы пытаемся обратиться к нему еще 5 раз, чтобы точно удостовериться, что к ресурсу невозможно получить доступ.

сбор внутренних ссылок, их html-докумнетов и текстов осуществлялся параллельно в 10 потоков, что позволило значительно ускорить процесс скрепинга по сравнению с применением последовательного подхода. Для организации мультипроцессинга использовалась python библиотека "concurrent".

Рандомизация выбора User-Agent при запросе к ресурсу
Настройка повторных попыток подключения к ресурсу
Мультипроцессинг
для безопасной работы мультипроцессинг подхода датафрейм с данными был разабит на 5 чанков по 2000 записей, для каждого из которых осуществлялся многопоточных сбора данных. После обработки каждого чанка была обеспечена задержка в 1 час перед началом обработки последующего, что обеспечило стабильную нагрузку на процессор и дополнительную защиту от блокировки со стороны хостинга

Чанкинг


apply
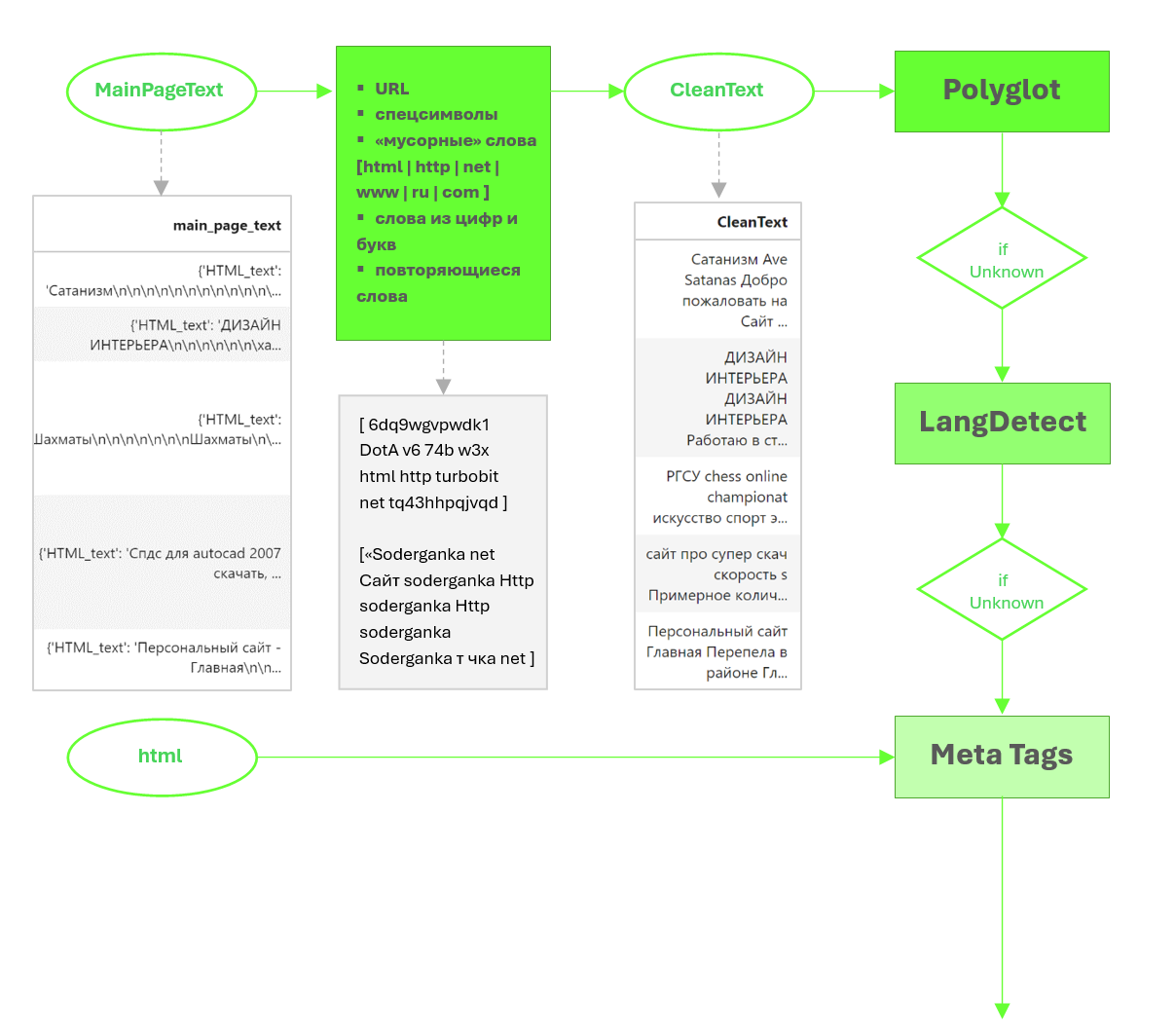
Основным источником данных для анализа сайтов narod.ru являются HTML DOM деревья их страниц. Они содержат тексты, стили, ссылки на дочерние страницы и медиа файлы, скрипты и многое другое.
Это поставило перед командой комплексную задачу по реализации алгоритма сбора html документов главных страниц, чтобы информация была собрана в максимально в полном объеме и была представлена в оптимальном для дальнейшего анализа виде.
Это поставило перед командой комплексную задачу по реализации алгоритма сбора html документов главных страниц, чтобы информация была собрана в максимально в полном объеме и была представлена в оптимальном для дальнейшего анализа виде.
каждый сайт является отдельным произведением искусства своего автора, поэтому сайты имеют очень разнообразную структуру верстки. Разработанный алгоритм должен максимально учитывать все особенности и все разнообразие тэгов, которое может встретиться на страницах.
Главная особенность работы со структурой сайтов narod.ru:
Примеры встроенной рекламы хостинга "Ucoz" на главных страницах сайтов narod.ru
Парсиннг текстов главных страниц
Парсинг текстового содержимого тэгов html-дерева главных страниц для дальнейшего анализа текста.


soup.get_text()
Мультипроцессинг. Скреппинг внутренних ссылок, HTML-документов и текстов
Организация пайплайна
Схема пайплайна
Формирование полныхадресов главных страниц
Формирование адреса главной страницы сайта для доступа к данным.
Скрэпинг HTML-документов главных страниц
Очистка HTML- документов от рекламы Ucoz
Удаление элементов HTML DOM дерева, содержащие рекламные блоки хостинга Ucoz.
Первым шагом, необходимым для доступа к сайтам, является формирование полных адресов страниц для дальнейшего обращения по ним с помощью отправки HTTP запросов
Результаты преобразования имен доменов в полные адреса
Сбор html-документов главных страниц для доступа к ее элементам.
Диаграмма последовательности работы алгоритма по сбору html документов главных страниц
После миграции сайтов "народа "на хостинг Ucoz, абсолютно во все сайты были интегрированы рекламные блоки данной компании, что с точки зрения анализа html структуры сайтов является "шумом" данных, который требовалось очищать для дальнейшего корректного анализа текстов.
Пример скрипта рекламы Ucoz в коде страницы:
В результате анализа устройства подобный рекламных блоков
нам удалось разработать инструмент их очистки,
что позволило не только удалить "шум", но и уменьшить
размер самих данных.
нам удалось разработать инструмент их очистки,
что позволило не только удалить "шум", но и уменьшить
размер самих данных.
После очистки html-структур от рекламы Ucoz, с каждой главной страницы с помощью пакета BeautifulSoup был извлечен текст, для проведения дальнейшего анализа на его основе.
Успешно собранные HTML-структуры главных страниц не дают полное представление о природе и устройстве сайта: на главных страницах может быть мало контента или главная страница может представлять из себя приветственный блок к кнопкой "Войти на сайт". Подобные случаи на выходе дают очень мало информации, что препятствует их дальнейшему анализу.
Помимо этого, нужно помнить об уникальности и авторском подходе для каждого из сайтов. Дизайн сайтов народа не содержит определенного паттерна проектирования, на который можно было ориентироваться - каждая страница каждого сайта может содержать уникальную верстку, цвет и семейство шрифтов, а также различный медиа контент.
Чтобы полностью описать характеристики сайта с точки зрения данных, необходимо собрать информацию о со всех его страниц.
Помимо этого, нужно помнить об уникальности и авторском подходе для каждого из сайтов. Дизайн сайтов народа не содержит определенного паттерна проектирования, на который можно было ориентироваться - каждая страница каждого сайта может содержать уникальную верстку, цвет и семейство шрифтов, а также различный медиа контент.
Чтобы полностью описать характеристики сайта с точки зрения данных, необходимо собрать информацию о со всех его страниц.
Главная особенность процесса сбора контента с внутренних ссылок - частота запросов к одному и тому же сайту. Неправильная организация HTTP запросов к серверу, отсутствие задержек и маскировок на стороне клиента могут привести к блокировке со стороны хостинга, который в свою очередь детектирует и пытается предотвратить массовый сбор данных с его ресурса.
Также нужно учитывать, что в выборке с большой вероятности есть сайты, с большим количеством внутренних страниц и контентом на них, что делает неэффективным последовательное обращение и последующий сбор данных с каждого ресурса.
Учитывая данные особенности, мы разработали пайплайн сбора внутренних ссылок и последующего сбора их HTML-документов и текстов, используя следующие подходы:
Также нужно учитывать, что в выборке с большой вероятности есть сайты, с большим количеством внутренних страниц и контентом на них, что делает неэффективным последовательное обращение и последующий сбор данных с каждого ресурса.
Учитывая данные особенности, мы разработали пайплайн сбора внутренних ссылок и последующего сбора их HTML-документов и текстов, используя следующие подходы:
позволяет имитировать подключение с разных устройств, совершая запросы с одного устройства, что уменьшает вероятность блокировки со стороны хочтинга
при получении ошибки HTTP первого запроса к ресурсу, мы пытаемся обратиться к нему еще 5 раз, чтобы точно удостовериться, что к ресурсу невозможно получить доступ.
сбор внутренних ссылок, их html-докумнетов и текстов осуществлялся параллельно в 10 потоков, что позволило значительно ускорить процесс скрепинга по сравнению с применением последовательного подхода. Для организации мультипроцессинга использовалась python библиотека "concurrent".
Рандомизация выбора User-Agent при запросе к ресурсу
Настройка повторных попыток подключения к ресурсу
Мультипроцессинг
для безопасной работы мультипроцессинг подхода датафрейм с данными был разабит на 5 чанков по 2000 записей, для каждого из которых осуществлялся многопоточных сбора данных. После обработки каждого чанка была обеспечена задержка в 1 час перед началом обработки последующего, что обеспечило стабильную нагрузку на процессор и дополнительную защиту от блокировки со стороны хостинга
Чанкинг
apply
Основным источником данных для анализа сайтов narod.ru являются HTML DOM деревья их страниц. Они содержат тексты, стили, ссылки на дочерние страницы и медиа файлы, скрипты и многое другое.
Это поставило перед командой комплексную задачу по реализации алгоритма сбора html документов главных страниц, чтобы информация была собрана в максимально в полном объеме и была представлена в оптимальном для дальнейшего анализа виде.
Это поставило перед командой комплексную задачу по реализации алгоритма сбора html документов главных страниц, чтобы информация была собрана в максимально в полном объеме и была представлена в оптимальном для дальнейшего анализа виде.
каждый сайт является отдельным произведением искусства своего автора, поэтому сайты имеют очень разнообразную структуру верстки. Разработанный алгоритм должен максимально учитывать все особенности и все разнообразие тэгов, которое может встретиться на страницах.
Главная особенность работы со структурой сайтов narod.ru:
Примеры встроенной рекламы хостинга "Ucoz" на главных страницах сайтов narod.ru
Парсиннг текстов главных страниц
Парсинг текстового содержимого тэгов html-дерева главных страниц для дальнейшего анализа текста.
soup.get_text()
Мультипроцессинг. Скреппинг внутренних ссылок, HTML-документов и текстов
Организация пайплайна
Схема пайплайна


| name | label | type | description |
|---|---|---|---|
| domain | домен сайта | string | Домены сайтов с хостинга narod.ru |
| main_page_link | полный URL главной страницы сайта | string | Ссылка, ведущая на главную страницу сайта |
| main_page_html | словарь html-документов главной страницы сайта | string | Строка, содержащая словарь html-документов глвной страницы и фреймов главной страницы Словрь содержит ключи: - HTML - ключ содержит html-документ главной страницы сайта - {frame/iframe}HTML_{значение атрибута 'src' фрейма} - ключ содержит html-документ тэга frame/iframe главной страницы сайта Ключи могут принимать следующие значения: - строка с html-документом - код статуса http ответа в случае огибки получения доступа к сайту Для конвертации строки в словарь использовать ast.literal_eval(main_page_html) |
| main_page_text | словарь текстов, содержащихся на главной странице сайта | string | Строка, содержащая словарь текстов главной страницы сайта и фреймов главной страницы сайта Словрь содержит ключи: - HTML - ключ содержит текст главной страницы сайта - {frame/iframe}HTML_{значение атрибута 'src' фрейма} - ключ содержит текст в тэге frame/iframe главной страницы сайта Ключи могут принимать следующие значения: - строка с текстом - код статуса http ответа в случае огибки получения доступа к сай Для конвертации строки в словарь использовать ast.literal_eval(main_page_text) |
| main_page_numbers | числа от 1000 до 2024 в тексте главной страницы сайта | string | Содержит стоку списка чисел от 1000 до 2024, которые встречаются в тексте главной страницы сайта Для конвертации строки в список использовать ast.literal_eval(main_page_numbers) |
| main_page_phrase_numbers | контекст упоминания чисел атрибута main_page_numbers | string | Содержит строку списка частей текста главной страницы, к контексте которых упоминается число из атрибута main_page_numbers. Для конвертации строки в список использовать ast.literal_eval(main_page_phrase_numbers) |
| main_page_dating | числа от 2000 до 2024 в тексте главной страницы сайта | string | Содержит стоку списка чисел от 2000 до 2024, которые встречаются в тексте главной страницы сайта Для конвертации строки в список использовать ast.literal_eval(main_page_dating) |
| main_page_phrase_dating | контекст упоминания чисел атрибута main_page_dating | string | Содержит строку списка частей текста главной страницы, к контексте которых упоминается число из атрибута main_page_dating. Для конвертации строки в список использовать ast.literal_eval(main_page_phrase_dating) |
| main_page_warning | категория сенсетивного контента, присутствующего на главной странице сайта | string | Показывает, является ли главная страница сайта потенциально неприемлемой для просмотра. Если страница безопасна, то переменная содержит 0. В остальных случаях встречаются названия категорий в строчном виде: 'porn' (порнографический контент), 'drugs' (пропаганда наркотиков), 'bad_words' (ненормативная/грубая лексика), 'race_discr' (расовая дискриминация), 'suicide' (пропаганда суицида), 'minust' (запрещенные, нежелательные организации, фамилии лиц, признанных иноагентами), 'lgbt' (упоминание представителей ЛГБТ) |
| main_page_bad_word | слово, детектирующее категорию сенсетивного контента на главной странице сайта | string | Содержит слово, которое послужило тригером для присвоения главной странице категории сенсетивного контента |
| internal_links | словарь url адресов внутренних ссылок сайта | string | Содержит строку со списоком внутренних ссылок сайта Словрь содержит ключи: - путь к странице относительного адреса главной страницы Ключи могут принимать следующие значения: - код статуса http-ответа при попытке получения доступа к сайту Для конвертации строки в словарь использовать ast.literal_eval(internal_links) |
| main_page_text_clean | очищенный от спецсимволов текст главной страницы сайта | string | Содержит текст главной страницы, очищенный от спецсимолов |
| main_page_language_name | название основного языка главной страницы сайта | string | Содержит название основного языка главной страницы сайта |
| main_page_language_code | код основного языка главной страницы сайта | string | Содержит код основного языка главной страницы сайта |
| main_page_language_count | количество языков, встречающихся на главной странице сайта | integer | Содержит число языков, встречающихся на главной странице сайта |
| main_page_proper_nouns | именованые сущности, встречающиеся в тексте главной страницы | string | Содержит строку списка именованых сущностей текста главной страницы сайта |
| main_page_text_lemm | лемматизированный текст главной страницы сайта | string | Содержит лемматизированный текст главной страницы сайта |
| main_page_text_len | длина текста главной страницы сайта | float | Содержит длину текста главной страницы сайта |
| main_page_period | период дат в тексте главной страницы сайта | string | Содержит период дат в тексте главной страницы в формате "date_begin - date_ending" |
| main_page_date_begin | начало интервала дат из атрибута main_page_period | float | Содержит значение начала интервала дат из атрибута main_page_period |
| main_page_date_ending | конец интервала дат из атрибута main_page_period | float | Содержит значение конца интервала дат из атрибута main_page_period |
| duration | длительность периода активного существования сайта | float | Содержит длительность периода активного сузествования сайта как разницу значений атрбутов date_ending и date_start |
| preview_file_name | название файла со скриншотом главной страницы сайта | string | Содержит назвние файла со скриншотом главной страницы сайта |
Codebook финального датасета
Содержит атрибуты, полученные в результате сбора данных и анализа текста.

Анализ текстов
определение языка
маркировка сенситивного контента
детекция дат
маркировка сенситивного контента
детекция дат
Направления работы


Тестирование разных подходов
Искусственный мини-сэмпл из ~100 сайтов на разных языках.
ПРЯМОЕ ОПРЕДЕЛЕНИЕ
ОПРЕДЕЛЕНИЕ ЧЕРЕЗ СТОП-СЛОВА
LANGDETECT
POLYGLOT
NLTK
узкоспециализированный инструмент обработки текста – только определение языка
основан на категоризации текста исходя из n-грамм
доступно 55 языков
основан на категоризации текста исходя из n-грамм
доступно 55 языков
комплексный инструмент обработки текста – различные функции, в т.ч. определение языка
основан на библиотеке pycld2, которая, в свою очередь, зависит от библиотеки cld2
доступно 196 языков (для функции определения языка)
основан на библиотеке pycld2, которая, в свою очередь, зависит от библиотеки cld2
доступно 196 языков (для функции определения языка)
комплексный инструмент обработки текста - нет отдельной функции определения языка
возможный подход – поиск уникальных для каждого языка стоп-слов и, как следствие, вывод о языке страницы
мало языков – но можно добавить пользовательские списки стоп-слов для нужных языков
возможный подход – поиск уникальных для каждого языка стоп-слов и, как следствие, вывод о языке страницы
мало языков – но можно добавить пользовательские списки стоп-слов для нужных языков
Разработка трехэтапного алгоритма
Этап 1 - POLYGLOT
Выбран в качестве первого этапа в связи с наличием ряда преимуществ:
- много языков, в том числе языки стран постсоветского пространства, актуальные для предполагаемого датасета
- бонус: языки малых народов (башкирский, татарский, чувашский, осетинский)
- возможность улавливать страницы с несколькими языками – через % уверенности
- много языков, в том числе языки стран постсоветского пространства, актуальные для предполагаемого датасета
- бонус: языки малых народов (башкирский, татарский, чувашский, осетинский)
- возможность улавливать страницы с несколькими языками – через % уверенности
Этап 2 - LANGDETECT
Выбран в качестве второго этапа, поскольку:
- является специализированным инструментом определения языка
- в некоторых случаях может лучше справляться с короткими текстами
Минус - нет % уверенности => не может определять несколько языков.
- является специализированным инструментом определения языка
- в некоторых случаях может лучше справляться с короткими текстами
Минус - нет % уверенности => не может определять несколько языков.
Этап 3 - Анализ метаданных
Выбран в качестве дополнительного этапа:
- в метатегах данные о языке содержались всего в 25% сайтов из выборки
- в качестве дополнительного этапа позволит определить язык для 2% сайтов
- в метатегах данные о языке содержались всего в 25% сайтов из выборки
- в качестве дополнительного этапа позволит определить язык для 2% сайтов
Итоговый алгоритм
Выводятся только те языки, в наличии которых уверенность >30%
В Languages и в MainLanguageName выводится полное название языка (language.name), а не сокращение (language.code), в MainLanguageCode – сокращенное (двухбуквенный код ISO – для последующей работы с инструментами анализа текста)
Включено условие по минимальной длине текста, необходимой для определения языка – 80 знаков, без учета знаков препинания, пробелов, переноса строки => в случае, если текста меньше, он отмечается как Unknown и т.о. не влияет на результаты анализа
С этой же целью установлено ограничение – если распознан только один язык, и уверенность при этом <30% - отмечать язык как Unknown
В Languages и в MainLanguageName выводится полное название языка (language.name), а не сокращение (language.code), в MainLanguageCode – сокращенное (двухбуквенный код ISO – для последующей работы с инструментами анализа текста)
Включено условие по минимальной длине текста, необходимой для определения языка – 80 знаков, без учета знаков препинания, пробелов, переноса строки => в случае, если текста меньше, он отмечается как Unknown и т.о. не влияет на результаты анализа
С этой же целью установлено ограничение – если распознан только один язык, и уверенность при этом <30% - отмечать язык как Unknown
* Для языков, обнаруженных на втором или третьем этапе, по умолчанию присваивался показатель 100%
** «Основным» считался язык, для которого % уверенности выше 40%
** «Основным» считался язык, для которого % уверенности выше 40%
Дальнейшие направления работы



Провести анализ языка на текстах всех страниц
Разработать решение проблемы неверного определения языка в связи с наличием сбитой кодировки текста
Разработать алгоритм по распознаванию текста со скриншотов и его учета при определении языка
Разработать решение проблемы неверного определения языка в связи с наличием сбитой кодировки текста
Разработать алгоритм по распознаванию текста со скриншотов и его учета при определении языка
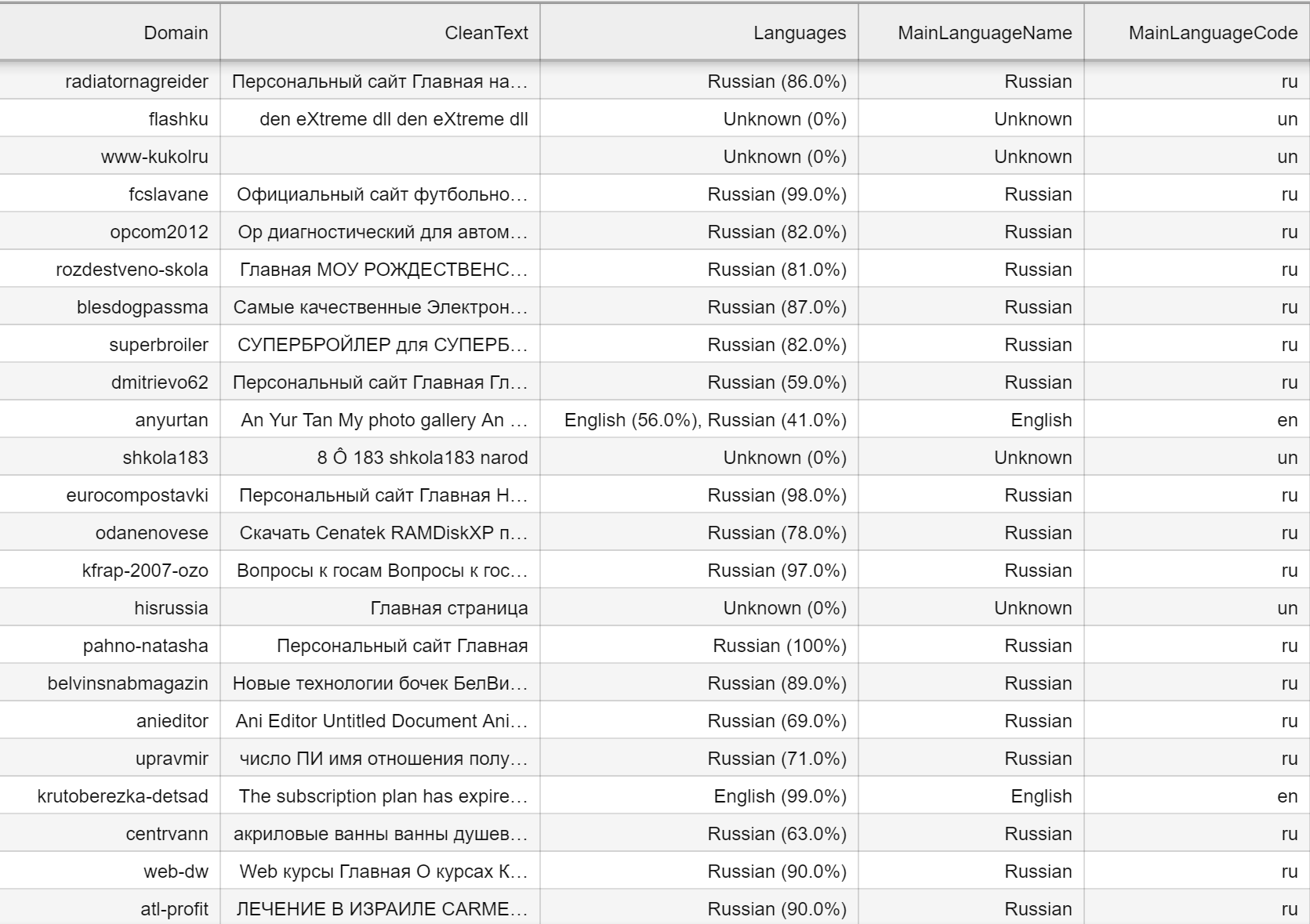
Пять колонок:
˗ Domain - для идентификации
˗ Languages - обнаруженный(-ые) язык(-и) + % уверенность в нем(них)*
˗ MainLanguageCode - код «основного» языка**
˗ MainLanguageName - полное наименование «основного» языка
- LanguageCount - количество языков
˗ Domain - для идентификации
˗ Languages - обнаруженный(-ые) язык(-и) + % уверенность в нем(них)*
˗ MainLanguageCode - код «основного» языка**
˗ MainLanguageName - полное наименование «основного» языка
- LanguageCount - количество языков
Сенситивный контент

*Фильтрация основана на Законе «О защите детей от информации, причиняющей вред их здоровью и развитию»
8%
сайтов из выборки содержат потенциально неприемлемый контент
Предобработали тексты
Составили списки со словами, указывающими на запрещенную тематику*
Проверили наличие этих слов на главных страницах сайтов
Записали переменные warning и bad_word в случаях, когда фильтр сработал
Сенситивный контент. Алгоритм
Лемматизация текстов сайтов и удаление стоп-слов. Привели слова к базовой форме, чтобы унифицировать их и улучшить точность поиска.
Создание словаря по сенситивным темам. Потенциально запрещенными считались сайты со словами, указывающими на контент 18+, расовую дискриминацию, призыв к самоубийству, употребление наркотиков, ненормативную лексику. Кроме того, маркировали сайты, которые содержали названия террористических организаций и упоминание иноагентов.
Написание функции фильтрации. Разработали функцию, которая разбивала тексты на слова и проверяла их на присутствие в словаре запрещенных тем. Если слово совпадало с элементом словаря, создавалась переменная warning с названием запрещенной темы и переменная, указывающая на слово, вызвавшее срабатывание фильтра. Для детекции запрещенных организаций использовался другой алгоритм: их названия искали в датасете с именованными сущностями.
Создание словаря по сенситивным темам. Потенциально запрещенными считались сайты со словами, указывающими на контент 18+, расовую дискриминацию, призыв к самоубийству, употребление наркотиков, ненормативную лексику. Кроме того, маркировали сайты, которые содержали названия террористических организаций и упоминание иноагентов.
Написание функции фильтрации. Разработали функцию, которая разбивала тексты на слова и проверяла их на присутствие в словаре запрещенных тем. Если слово совпадало с элементом словаря, создавалась переменная warning с названием запрещенной темы и переменная, указывающая на слово, вызвавшее срабатывание фильтра. Для детекции запрещенных организаций использовался другой алгоритм: их названия искали в датасете с именованными сущностями.

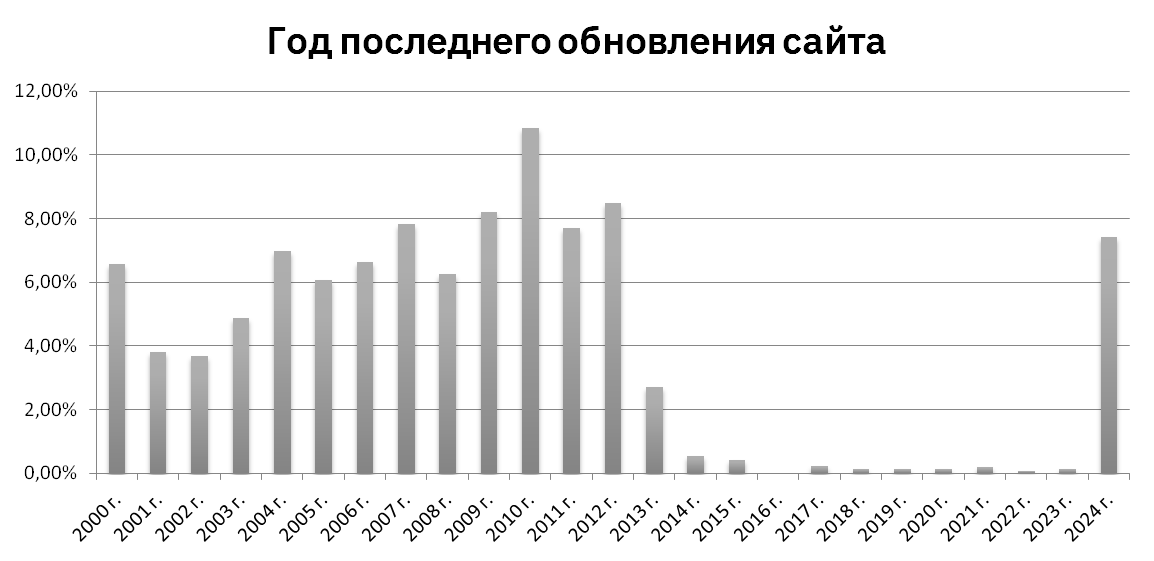

Детекция дат
Выявление ключевых паттернов упоминаемых на сайтах дат. Отсутствие единого тега, в котором бы упоминалась дата создания и дата последней модификации сайта исключила возможность использования библиотеки BeautifulSoup.
С помощью регулярных выражений выборка дат, которые встречаются на сайтах. Из них с использование контекста определение паттернов, выборка дат предполагаемой последней модификации.
Отдельный поиск с помощью регулярных выражений двойных дат, которые позволили определить среднюю продолжительность существования сайтов.
С помощью регулярных выражений выборка дат, которые встречаются на сайтах. Из них с использование контекста определение паттернов, выборка дат предполагаемой последней модификации.
Отдельный поиск с помощью регулярных выражений двойных дат, которые позволили определить среднюю продолжительность существования сайтов.
Скриншоты главных страниц позволяют:
по размеру файла понять объем информации, длину страницы
разработать автоматизированную визуальную классификацию web1.0
выявить сенсетивный контент
Скриншоты главных страниц

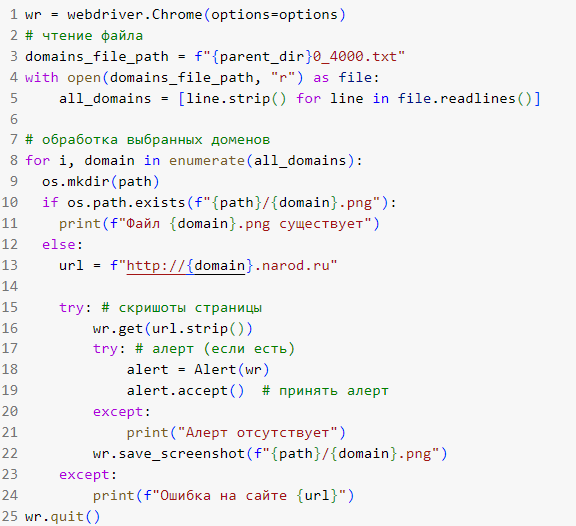
Создание интерактивного интерфейса
для исследования вселенной narod.ru

Функционал интерфейса*:
- Поиск сайтов Narod'а по названию домена
- Фильтрация сайтов Narod'а
*по упоминанию дат
*по предполагаемой дате создания
*по наличию и категории чувствительного контента
*по языку сайта

* Реализован с помощью Dash Plotly, Plotly Express, HTML
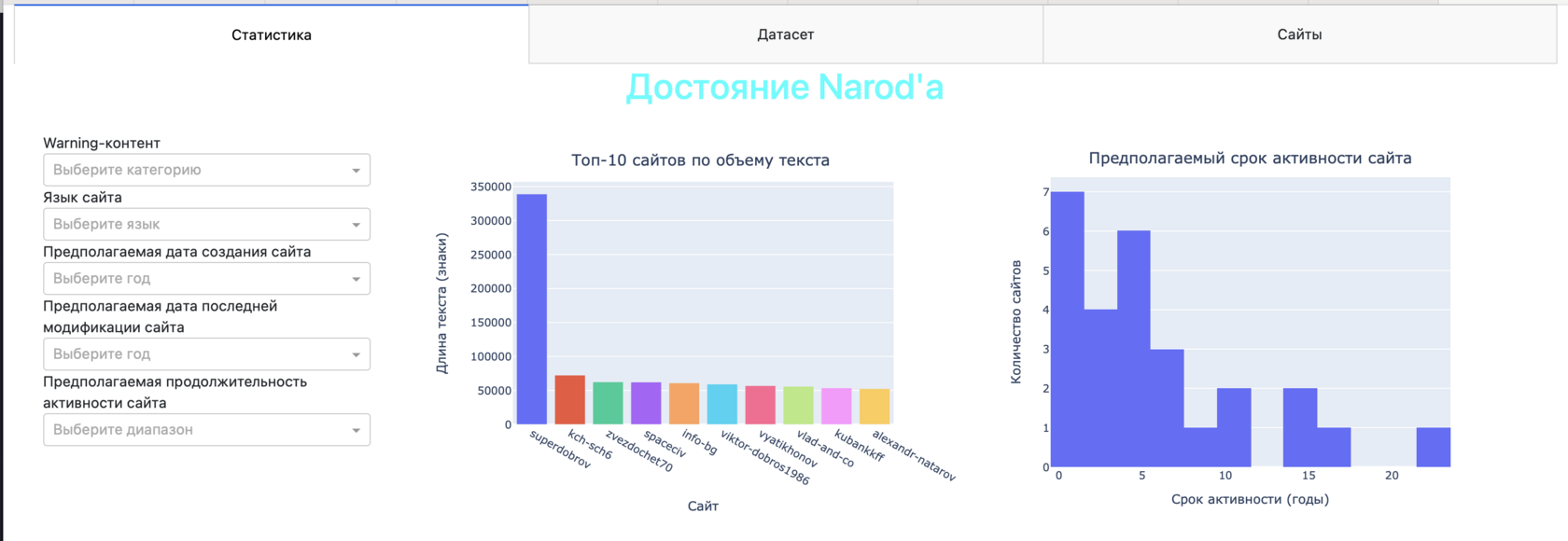
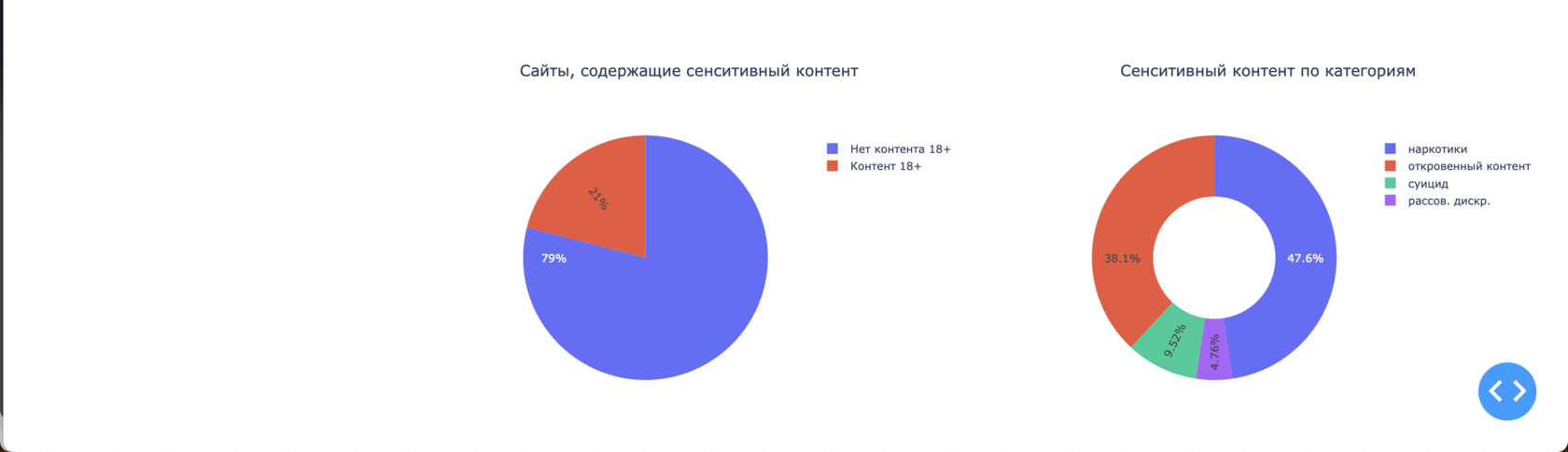
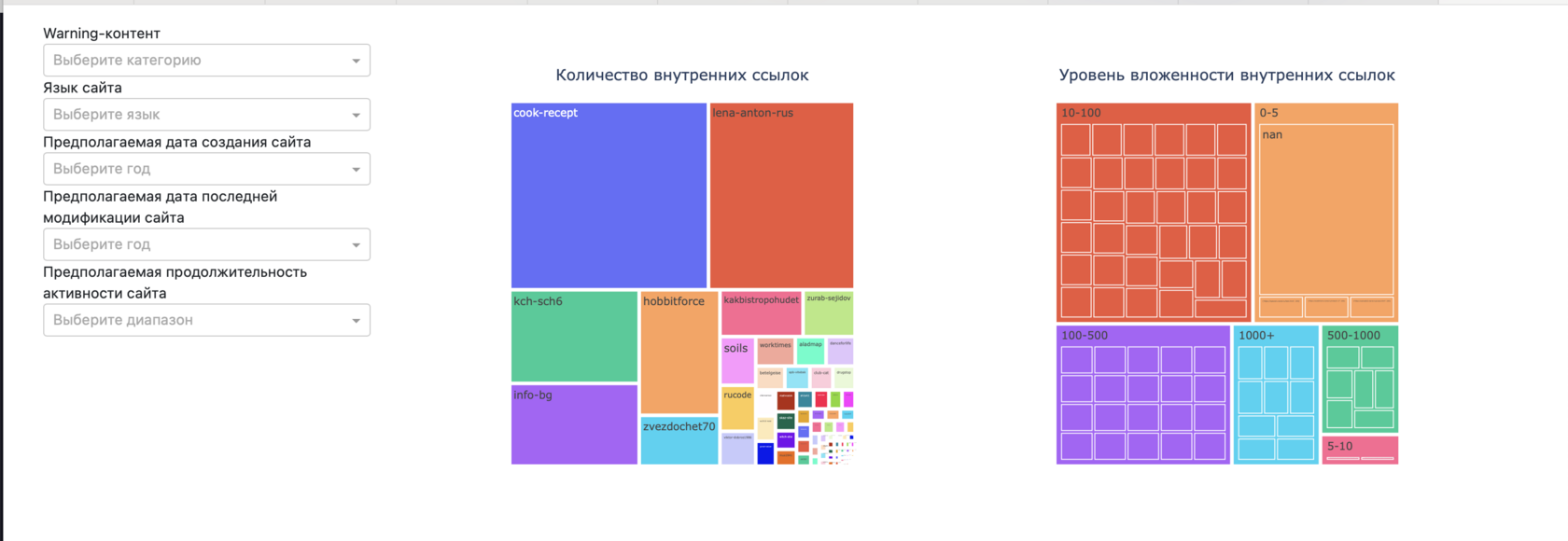

Вкладка «Статистика»
Вкладка «Датасет»
Позволяет увидеть итоговый датасет, сформированный в рамках проекта
Реализована возможность использования фильтров по:
- категории сенситивного контента
- основному языку сайта
- предполагаемой дате создания сайта
- предполагаемой дате последней активности сайта
- предполагаемому сроку активности сайта
По умолчанию отображается 10 рандомных строк датасета
При использовании фильтров отображаются 10 рандомных строк, соответствующих выбранным фильтрам (либо все строки, соответствующие выбранным фильтрам, если в датасете их менее 10)
Реализована возможность использования фильтров по:
- категории сенситивного контента
- основному языку сайта
- предполагаемой дате создания сайта
- предполагаемой дате последней активности сайта
- предполагаемому сроку активности сайта
По умолчанию отображается 10 рандомных строк датасета
При использовании фильтров отображаются 10 рандомных строк, соответствующих выбранным фильтрам (либо все строки, соответствующие выбранным фильтрам, если в датасете их менее 10)
Вкладка «Сайты»
Позволяет посмотреть информацию о выбранном сайте, включая:
- адрес страницы (ссылка кликабельна с CTRL)
- скриншот главной страницы
- наличие и категорию сенситивного контента
- язык(и) страницы
- упоминаемые даты
- наличие медиаконтента
Поиск осуществляется по наименованиям поддоменов сайтов
- адрес страницы (ссылка кликабельна с CTRL)
- скриншот главной страницы
- наличие и категорию сенситивного контента
- язык(и) страницы
- упоминаемые даты
- наличие медиаконтента
Поиск осуществляется по наименованиям поддоменов сайтов





Позволяет увидеть визуализированную дескриптивную статистику датасета, сформированного в рамках проекта
Реализована возможность использования фильтров по:
- категории сенситивного контента
- основному языку сайта
- предполагаемой дате создания сайта
- предполагаемой дате последней активности сайта
- предполагаемому сроку активности сайта
На вкладке отображаются графики: топ-10 сайтов по длине текстов, диаграмма распределения количества сайтов по предполагаемым срокам активности, круговые диаграммы, отражающие наличие и распределение по категориям сенситивного контента, а также древовидные диаграммы, отражающие данные по наличию и глубине внутренних ссылок на сайтах
При использовании фильтров отображаются графики переменных, соответствующих выбранным фильтрам
Реализована возможность использования фильтров по:
- категории сенситивного контента
- основному языку сайта
- предполагаемой дате создания сайта
- предполагаемой дате последней активности сайта
- предполагаемому сроку активности сайта
На вкладке отображаются графики: топ-10 сайтов по длине текстов, диаграмма распределения количества сайтов по предполагаемым срокам активности, круговые диаграммы, отражающие наличие и распределение по категориям сенситивного контента, а также древовидные диаграммы, отражающие данные по наличию и глубине внутренних ссылок на сайтах
При использовании фильтров отображаются графики переменных, соответствующих выбранным фильтрам
анализ CSS-стилей
тематическая кластеризация на основе текста и скриншотов главных страниц
анализ текста на основе содержимого всех вложенных страниц сайтов
сбор медиафайлов
анализ именованных сущностей
поиск именованных сущностей
тематическая кластеризация на основе текста
подключение приложение к БД Postgres
общее расширение функционала интерфейса
тематическая кластеризация на основе текста и скриншотов главных страниц
анализ текста на основе содержимого всех вложенных страниц сайтов
сбор медиафайлов
анализ именованных сущностей
поиск именованных сущностей
тематическая кластеризация на основе текста
подключение приложение к БД Postgres
общее расширение функционала интерфейса
Перспективы развития проекта



MVP
minimum viable product

- Пакет функцийРепозиторий на GitHub с функциями по работе с Narod`ом
- ДатасетНабор csv-файлов с данными сайтов
- ИнтерфейсГрафический интерфейс на базе Plotly Dash для исследования сайтов на Narod`е.
P.S.: все использованные в презентации gif-ки найдены на сайтах naroda
Замечательная галерея 2000-х в gif

Котов Михаил


@t4m4g0tch1
Александра Горваль

Наталья Дмитриева

@Natali_DmV
Наталья Горбачева

@nightmarenati
Ксения Зайцева

@kzaitsewa
Иван Бибилов

pandan.eu@yandex.ru
Анна Козлова

pandan.eu@yandex.ru
Татьяна Максимова

@tanyammm9
Все звезды:
Все звезды:
Кураторы проекта:
Кураторы проекта:


@themillcake
