О проекте
Карта основана на данных проекта «Прожито». Проект был создан в 2015 году как площадка для сбора и публикации текстов личных дневников на русском и украинском языках. Сейчас в корпусе «Прожито» около 2000 дневников XVIII-XX веков, из которых 500 — первопубликации проекта. Это более полумиллиона подневных записей.
Центр «Прожито» принимает на хранение цифровые копии источников и электронные тексты. Если вы хотите передать дневник, свяжитесь с командой проекта.
Beautiful Soup
NLTK, Pandas
MyStem
API Yandex.Карт
Для поиска мы использовали библиотеку Beautiful Soup и скрейпили Википедию — список всех улиц по районам и список федеральных объектов культурного наследия Санкт-Петербурга.
Шаг 1: Скрейпинг списка улиц по районам
Результат: Словарь по категориям (районы), внутри категории список улиц и ссылка на страницу улицы в Википедии.
Шаг 2: Скрейпинг списка достопримечательностей
Результат: Словарь с одной категорией (Федеральные объекты культурного наследия Санкт-Петербурга), внутри категории список достопримечательностей и ссылка на страницу достопримечательности в Википедии.
В дальнейшем планируем расширить этот список достопримечательностей регионального значения и просто значимыми местами Петербурга.
Шаг 3: Скрейпинг страницы объекта в Википедии
Результат: Список словарей, где по каждому объекту собрана такая информация:
- название объекта;
- гугл-координаты;
- фото;
- старое название;
- тип объекта (определялся по названию);
- район (только для улиц).
Всего было собрано 2516 объектов.
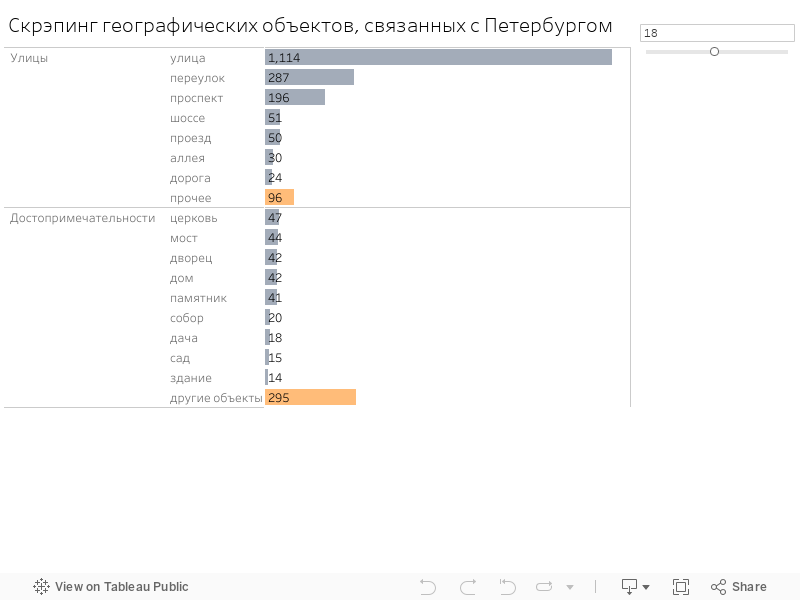
Мы использовали pandas и NumPy для осуществления всех операций с DataFrame. Библиотека NLTK была задействована в предобработке данных (при таких процедурах как токенизация и чистка текстовых данных). Лемматизация осуществлялась при помощи программы Яндекса MyStem.
Шаг 1. Предобработка и векторизация текстовых данных
Результат: очищенные и лемматизированные списки топонимов, очищенный и лемматизированный датасет дневниковых записей, частотные списки, word embeddings, графики.
Шаг 2. Поиск топонимов в датасете дневниковых записей, формирование петербургских датасетов
Результат: два датасета петербургских дневниковых записей 1953-1964 гг. по улицам и достопримечательностям Петербурга (всего 529 строк) с информацией о каждом топониме, встречающемся в дневниковых текстах.
Для каждой записи мы сохранили следующую информацию:
- название топонима;
- класс объекта (достопримечательность или геоним);
- тип объекта (парк, музей, улица и пр.);
- координаты;
- фото объекта (ссылка);
- дневник (текст);
- автор (номер в корпусе "Прожито");
- полное имя автора;
- возраст автора в момент написания дневника;
- пол;
- дата создания дневника;
- год создания дневника;
- район (только для геонимов);
- возрастная категория (до 30, от 30 до 60, после 60).
Бонус. Анализ тональности дневниковых записей
Результат: датасет с оценкой тональности каждой дневниковой записи, графики.
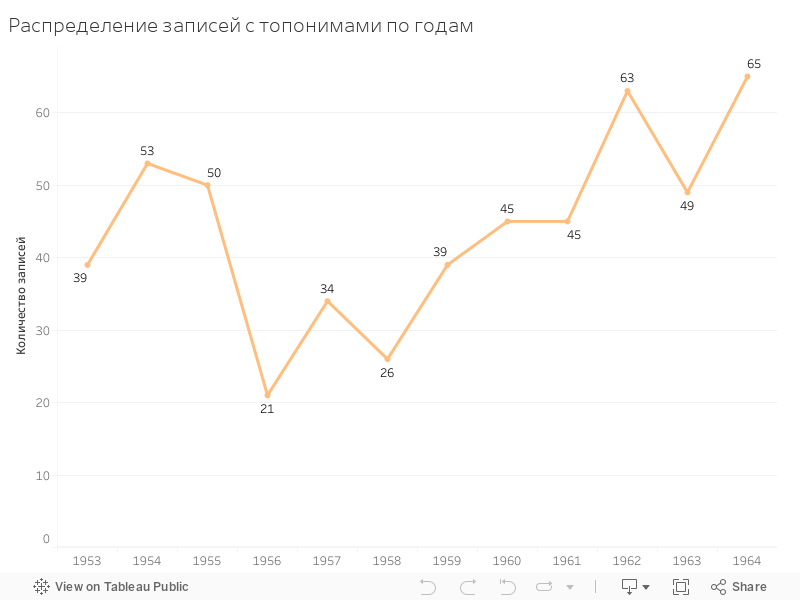
Почему так получилось?
- Много топонимов, которые встречаются сразу в нескольких городах: улица Ленина, Пушкинская улица, Эрмитаж, Новодевичье кладбище и пр. Сейчас мы это никак не учитываем.
- Авторы дневников вспоминают события прошлого, но они не относятся к выбранному периоду.
- В текстах дневниковых записей топонимы нечасто встречаются в той форме, в которой мы парсили их с Википедии. Неформальные названия (Мариинка, Невский), отсутствие номера (Советская) или сокращения (ул. Большая Зеленина) не позволяли определить присутствие большой части топонимов в дневниковых записях.
- Предобработка и лемматизация текстов дневниковых записей сыграла не лучшую роль в поиске топонимов. Тихая улица, Большая улица, Липовая аллея, Берёзовая аллея, - первые части всех этих топонимов воспринимались машиной как прилагательные, стоящие перед существительными.
- Наш метод поиска нередко «ловил» непетербургские топонимы, в состав которых входили петербургские топонимы (Вальдорф-Астория).
- Нередко важно знать контекст или обладать информацией об авторе дневника: «На улице Черняховского инфернальная берёза призрачная, горькая, над ней фиолетовый фонарь подобен александриту».
Шаг 1. Создание массива/списка, содержащего данные обо всех записях из датасета, в формате JSON посредством Python
Результат: готовый массив с данными обо всех записях.
Шаг 2. Использование API Yandex.Карт и JavaScript для отображения данных
Результат: Развернутая карта, лежащая в облаке. Все точки из нашего массива отображаются на ней.
Шаг 3. Изменение стиля текста в балунах через HTML
Результат: Единый формат отображения записей, который включает:
- название топонима;
- запись из дневника с упоминанием топонима;
- автора;
- его возраст.
Шаг 4. Фильтрация дневниковых записей через определения стиля отображения точек на карте
Результат: Фильтрация по типу объекта (геонимам, достопримечательностями) и гендеру.
- улучшить алгоритм определения топонимов в дневниках, чтобы убрать выявленные ошибки;
- добавить на карту записи других исторических периодов (Русская революция, Великая Отечественная война, Перестройка, 90-е годы и т.д.);
- добавить фильтрацию по различным историческим периодам;
- улучшить визуализацию данных (добавить фото топонимов, элементы верстки, изменить подложку)
Проект создан студентами и кураторами программы "Прикладной анализ данных" Европейского университета в СПб и Яндекса.
