
Прожито
Это текстовый корпус эго-документов, созданный как площадка для сбора и публикации текстов личных дневников. Общий объем корпуса — 16 тысяч документов из государственных и домашних архивов за период XVIII–XXI веков.
Центр «Прожито» предложил студентам программы ПАНДАН задачу — разработать прототип механизма рекомендации похожих записей дневников для пользователей архива «Прожито».
В рамках проекта мы исследовали, какие признаки мы можем использовать для поиска похожих документов: на основе содержания текстов, метаинформации и данных об авторах.
Мы подготовили интерактивный прототип, в котором документы подбираются на основе расстояний между векторными представлениями текстов и подготовили рекомендации для реализации системы поиска на сайте «Прожито».
потреблении контента
чаще всего выбирают вместе
с нужным
понравились ли им
тексты/книги
записей/текстов
Изучение структуры корпуса «Прожито», сбор статистики по корпусу, предобработка текстов записей
Разметка текстов дневников участниками проекта
Запуск прототипа системы поиска похожих дневниковых записей
Как устроены данные в архиве «Прожито»

Очистка текстов записей
в современной и дореволюционной орфографии.
Они выгружены в raw-виде и содержат html/xml-теги.
В тексте есть редакторские пометки в [ ].
В [ ] и { } также заворачиваются восстановленные лакуны.
«Вставные» документы (напр., вклеенные) иногда оформляются оборотом в <>, например:
[В тетрадь подшито письмо Липкину от матери — Прожито.] < Добрый вам день, дорогие, Матвей Евсеевич, ...
Проблемами в исходных данных, с которыми мы столкнулись
- 1Ошибки, которые не позволяли связать дневниковые записи с биографиями авторов по id.
- 2Ошибочная или отсутствующая информации об авторах (годы рождения или смерти авторов дневников).
- 3Наличие, помимо самих дневников также автобиографий, записей наблюдения за новорожденными и др.
- 4Короткие записи, состоящие из одного предложения.
- 5Упоминание в одной дневниковой записи нескольких дней (иногда больше месяца и даже года).

Извлечение метаданных

Векторизация
Мы попробовали сразу несколько способов векторизации дневниковых записей
- TD-IDF-векторизация лемматизированного текста с последующим PCA-сокращением размерности01
- векторизация общедоступными предобученными моделями разного размера и размерности,
имеющими высокий рейтинг
в публичных бенчмарках,
в т.ч. для русского языка02
Суммаризация
Чтобы повысить качество векторизации, мы пробовали суммаризировать длинные тексты с помощью GPT-трансформеров и настраивать токенизаторы моделей, а чтобы дополнительно обогатить набор данных, решили дополнительно кластеризовать тексты записей в несколько итераций, выделив основные тематические теги.
Для кластеризации (группировки) текстов дневниковых записей была использована модель BERTopic. Полученные при кластеризации тематические теги упростят поиск похожих записей.
Метод кластеризации K-means позволил четко определить количество кластеров и избежать появления большого кластера с «шумом».
В результате проведенной кластеризации были выделены следующие тематические теги

Разметка данных
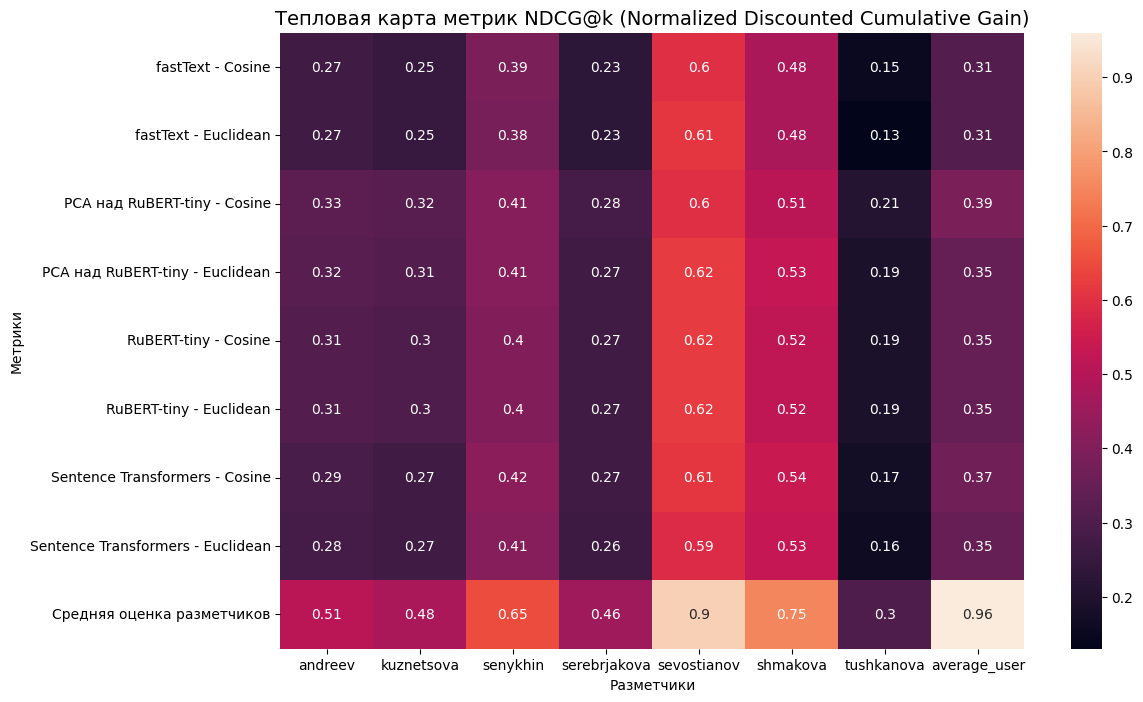
Мы решили исследовать, какие тексты дневников выглядят похожими для выборки «обычных пользователей», и выбрать метрики сходства на основе этих данных. Для этого нам нужна была система разметки данных, которую мы развернули на базе open-source платформы Argilla.
Каждый разметчик оценивал схожесть около 1300 пар записей по шкале от 1 (наименее похожи) до 4 (наиболее похожи)
Интерфейс нашей системы для разметки текстов дневниковых записей выглядел так


Результаты разметки


Прототип рекомендательной системы На основе проведенной векторизации и кластеризации текстов дневниковых записей был разработан прототип рекомендательной системы. В прототипе используется косинусное расстоение между векторами, полученными с помощью PCA над rubert-tiny и теги, выделенные при помощи BERTopic. Ознакомиться с прототипом можно здесь. Исходный код прототипа доступен на GitHub. |
- Тушканова ОльгаКуратор проектаКандидат технических наук, доцент факультета социологии ЕУСПб, старший научный сотрудник СПб ФИЦ РАН
- Сенюхин АлексейКуратор проектаРедактор корпуса текстовых данных Центра изучения эго-документов «Прожито»
- Андреев НиколайСтудент программы ПАНДАН
- Кузнецова АннаСтудент программы ПАНДАН
- Севостьянов АлександрСтудент программы ПАНДАН
- Серебрякова АлександраСтудент программы ПАНДАН
- Шмакова АннаСтудент программы ПАНДАН
